従来のデータ基盤の課題とデータレイクハウスの台頭
近年、企業におけるデータ活用の幅が急激に広がっています。統計解析やBIに加え、現在では生成AIの活用も当たり前になりつつあります。このような背景のもと、システム管理者、データエンジニア、データサイエンティストに加えて、生成AIエンジニアなど、多様なロールの方がデータを活用するようになっています。
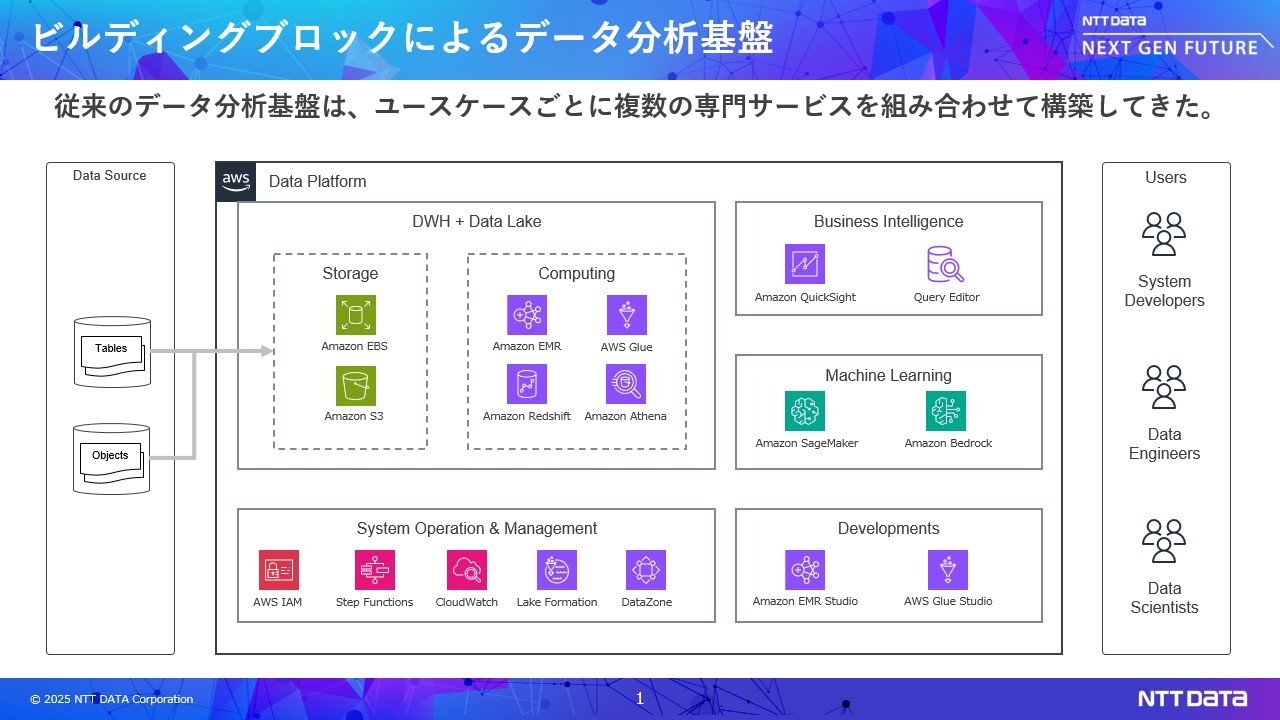
その結果、データ分析基盤に求められる要件も高度化・多様化しています。従来はETLツール、DWH、データレイク、BIツール、機械学習、生成AIといった個別のサービスを組み合わせ、ビルディングブロックで構築していました。ユースケースの増加に伴い、組み合わせるサービスも増え、いくつか課題が浮上しています
- 複数サービス/UIの使いこなしの難しさと生産性の低下
たとえば、データエンジニアが構造化データをAWS Glueで分析し、非構造化データをGlueで処理し、Amazon Quicksightで可視化し、さらにAWS Step Functionsでパイプライン化する、といった煩雑な操作が求められます。難易度が高いだけではなく、複数サービスを行き来するため生産性が低下します。
類似の言語(例:SQLとPython)を使うツールが混在するため、スクリプトの管理も多重管理になりがちであり複雑化します。
管理者視点でも、サービスが増えるほど設計や構築の難易度が高まります。IAMやVPCなどのセキュリティ・ネットワーク設計・構築はサービスごとに異なり、共通ポリシーを設計するには個々のサービスについて高度な知識が求められます。さらに、サービスごとの運用(バージョンアップ、リソース管理、性能チューニング、コスト管理)も検討する必要があります。
DWHは独自のフォーマットでデータを保存し、データレイクはオープンフォーマットでデータを格納します。データ分析では、これら異なる形式のデータを横断的に扱う必要があり、データの移動や同期が必要になりますしかし、データ量が増加する現在、これらの処理は複雑かつコストも高く、データの重複や整合性の問題が発生しやすくなっています。
DWHはテーブルベースで細かなアクセス制御が可能ですが、データレイクではファイルやディレクトリへのアクセス制御が主流です。セキュリティモデルが異なるため、データ移動時に機密情報が誤って公開されたりしないよう注意する必要もあります。
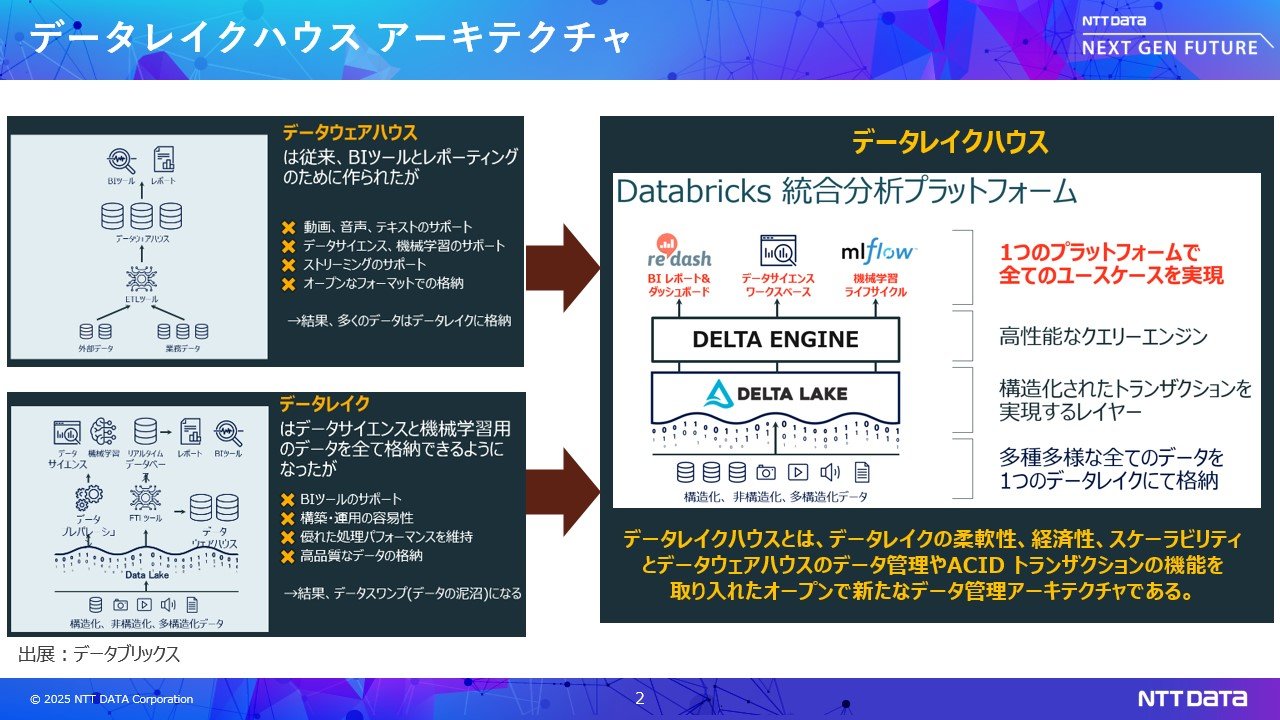
こうした課題に解決するために、複数のユースケース(データエンジニアリング、BI、AI、生成AI)を1箇所で管理できるよう「データレイクハウス」アーキテクチャと呼ばれるオールインワンのプラットフォームが登場してきました。
データレイクハウスは、データウェアハウスとデータレイクを組み合わせた造語です。DWHのデータ管理やACIDトランザクション機能と、データレイクの柔軟性、経済性、スケーラビリティを取り入れた新しいデータ基盤です。データレイクハウス・オールインワンはDatabricks社が提唱しはじめたもので、NTTデータはいち早くパートナー契約を結び2025年1月には出資も行うなど強固なアライアンスを築いています。
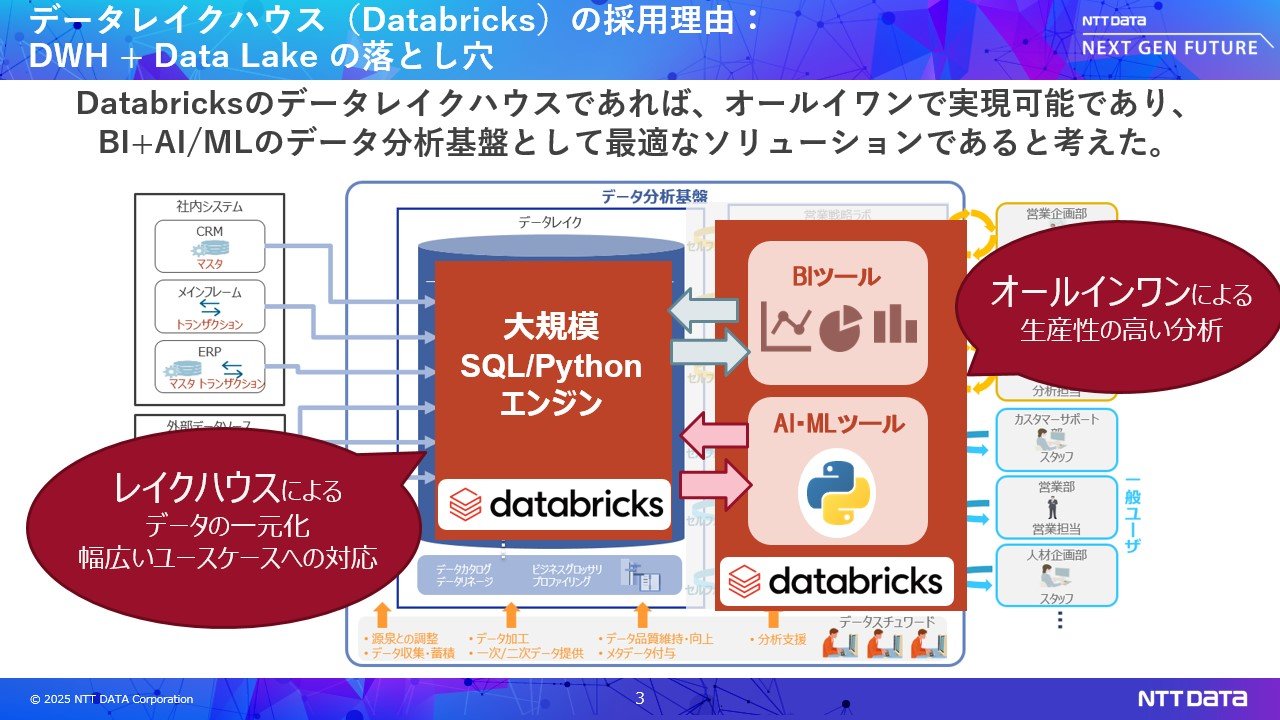
今回ご紹介するAmazon SageMaker Unified Studioは、AWSのデータレイクハウスアーキテクチャのオールインワンプラットフォームです。S3上にIceberg形式でデータを一元管理し、複数のユースケースにワンプラットフォームで対応します。UIも1つに統合され効率的に分析を行えます。
データレイクハウスの導入事例
Databricksを用いた事例をご紹介します。とあるお客様では、DWHを中心に据えたデータ分析基盤を運用し、BIでのデータ活用に成功していました。しかしAI活用が始まると、新たな課題が発生しました。
AIに必要なデータは通常、ファイル形式であり、DWHでのSQL処理だけでは対応しきれません。結果として、データサイエンティストがデータをローカルにダウンロードし、加工・学習を行う必要が生じ、データ転送時間やディスク容量の増加、学習処理ではハイスペックなローカル環境が必要、ダウンロードによりデータガバナンスが失われる、といった課題に直面していきました。
これを回避するために、Amazon AthenaやAmazon SageMakerAIを組み合わせることも試みましたが、データのバケツリレーが発生して効率が悪い、習熟が難しいといった課題が残りました。これらの悩みを解決できるのが、データレイクハウス オールインワンプラットフォームでした。BIからAIにユースケース拡張を考えられているお客様は採用を検討されることをおすすめします。
Amazon SageMaker Unified Studioに関する取り組み
我々のチームは「Trusted Data Foundation」というブランド名で、長年にわたりデータ分析を構築するソリューションを提供してきました。しかしお客様の課題をすべて解消できないという悩みを持っていたところに、データレイクハウスを知り、普及活動を加速させてきました。そしてAWS様からデータレイクハウスサービスがリリースされるということで、意見交換をしながらクォートの、AWS様と共同での技術検証記事などの執筆などを行っております。

Amazon SageMaker Unified Studioのデモ
機械学習モデル開発における一連の流れをAmazon SageMaker
Unified Studioを使ってどのように効率化できるか、デモを交えてご紹介します。
これまでAWSを使った機械学習モデルの開発では、システム管理者・データエンジニア・データサイエンティストがそれぞれ異なるサービスを用いて作業する必要があり、非常に煩雑でした。たとえば、アクセス制御にはIAMやWS Lake Formation
を利用し、さらにVPCなどでインフラ構築をする必要がありました。またデータサイエンティストはAthenaやAWSGlue、機械学習モデル開発にはAmazon SageMaker AIを使い、パイプライン化にはAmazon MWAAなどのワークフローツール、といった具合で、組み合わせるサービスが増えるほど認証方式やアクセス制御などの設計が必要になり、複雑な運用とセキュリティ対策が求められてきました。
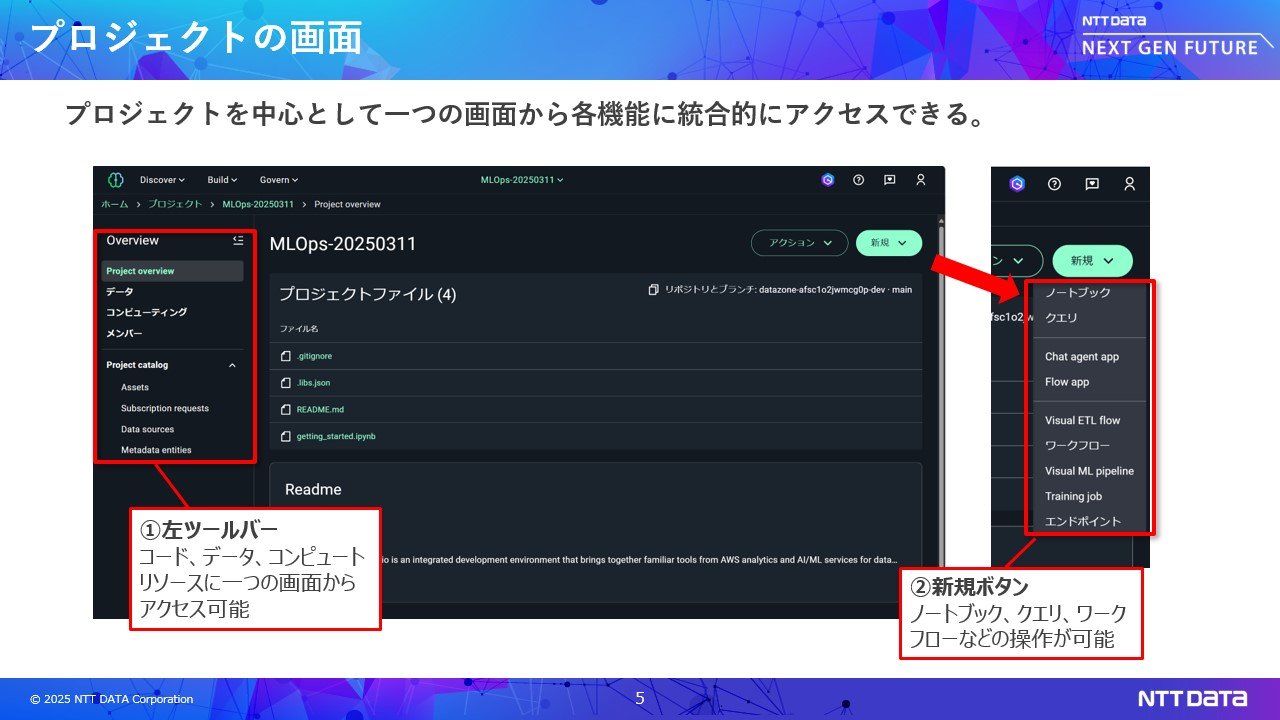
この複雑さを解消するために登場したのがAmaozn SageMakeUnified Studioです。システム管理者はすべての機能を1度に構築可能で運用や管理が容易になり、利用者にとっては統一的なUIで利用のハードルが低いというメリットもあります。
まず、環境構築ではシステム管理者が「プロジェクト」という単位で機械学習環境を払い出しします。これまでは都度、分析者の依頼に基づき個別対応が必要でしたが、Unified Studioでは数クリックで環境を作成可能です。プロジェクトテンプレートを選ぶだけで必要なAWSリソースが自動的に構築されるため、迅速な立ち上げが可能になります。
続いて、データエンジニアが行うデータ探索についてです。Unified Studioでは統合されたデータカタログ機能を使うことで、キーワード検索で横断的にデータを発見・確認できます。メタデータを使った検索も可能です。これまではAmazon
やAmazonなどに分散したデータにアクセスするのに複数のサービスを横断する必要がありましたが、これらのデータを1つの画面から探索できるようになりました。またデータの可視化もクリック操作で可能です。
次はデータ加工プロセスです。Unified Studioではノートブック上でGlueを使ったコーディングを実施するとデータ加工処理の開発が可能です。Amazon RedshiftやAmazon EMRを活用した加工処理も1つの画面で行えます。これまで分散していたコードが1つの場所に集約され、利用しやすくなります。
データサイエンティストによる機械学習モデルの開発も、同じノートブック上で、Unified Studioに統合されたAmazon SageMakerAIを利用して行います。
学習結果の管理はTraining Jobを使い、学習したモデルはエンドポイント機能を用いて2クリックでAPI化され、機械学習モデルを業務アプリケーションに組み込むことができます。
そしてパイプライン化ですが、学習モデルはデータの変化に対応するために定期的に再学習させる必要があり、再学習を自動化するためのパイプライン化を行います。Unified Studioではデータサイエンティスト自らパイプライン開発が行えます。
まとめ
Amazon SageMakerUnified Studioはデータ管理、BI、機械学習など多様なユースケースに対応し、従来のビルディングブロックの煩雑な構成を大きく簡素化します。とくに、BIからAIへと活用を拡張しようとするお客様にとって、ご利用をぜひご検討いただければと思います。
ただしUnified Studioはあくまでツールであり、実際に使いこなすにはデータマネジメントやMLOpsといった専門知識が欠かせません。NTTデータではそうした領域への支援も行っておりますので、ご関心があればぜひお問い合わせください。







