データドリブン経営の課題
データドリブン経営は今日、どの企業様にとっても喫緊の課題と思いますが、それには「意思決定のサイエンス化」の高度化が重要です。
意思決定のサイエンス化を実現する仕組みは、主に 3 つあると考えています。
1 つ目が、データを集めて素早くユーザに提供し意思決定を高速化する「情報ポータル」。
2 つ目は、分析をデータサイエンティストだけでなく一般の社員もできるようにして、各業務の意思決定を高度化する「セルフサービス分析」です。いま流行しているデータの民主化という言葉に言い換えてもいいと思います。
3 つ目は、実際に作った AI のモデルをサービスや業務に組み込んで、意思決定を自動化し、さらに良いサービスを提供していく「AI の業務組み込み」です。
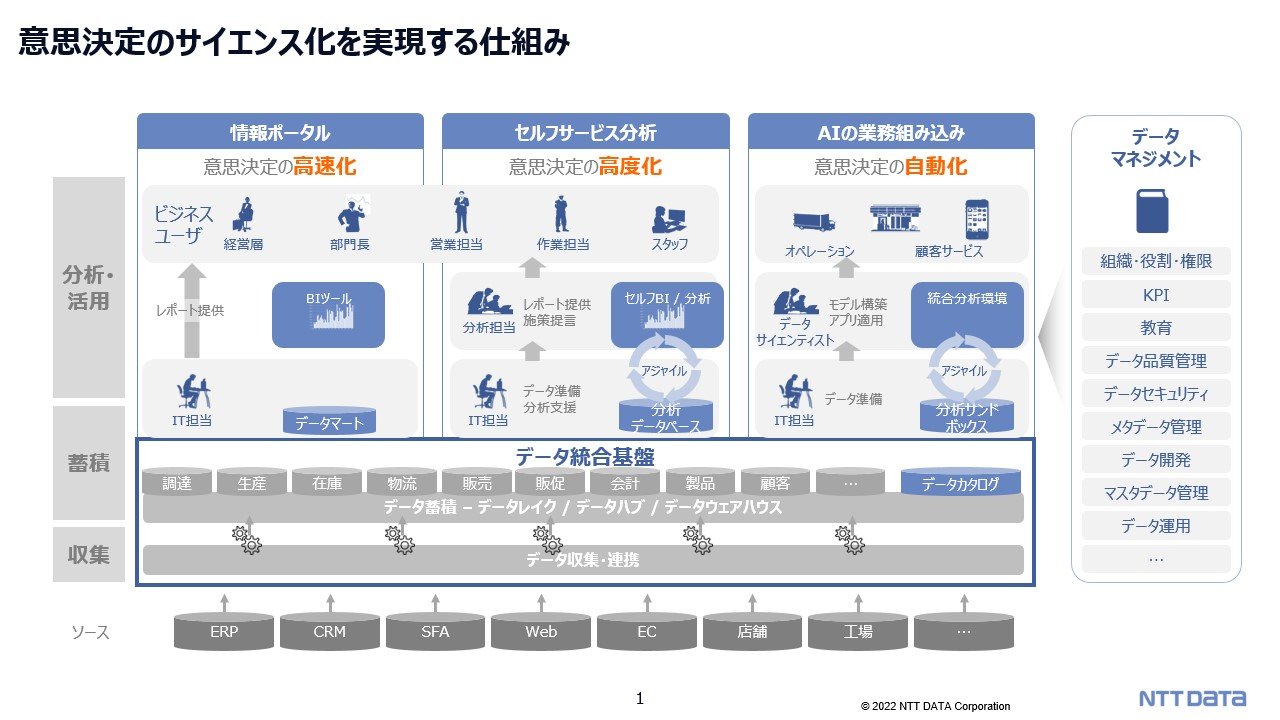
とはいえ実際にデータドリブン経営を実現するうえでは、ビジネス面、データ面、人・組織、基盤面などでさまざまな課題が現われてきます。
ビジネス面では、効果がなかなか上がらない、高いビジネス効果が見込めるテーマを創出できない、といった課題があります。
データ面では、法令やセキュリティが足かせとなって流通や活用ができないというお客様が多くおられます。
人・組織面では人財不足に加えて、CoE 組織が機能しない、人財の活躍の場がないというお客様が非常に多くなってきました。
そして技術・基盤面ではどれを使ったらいいのか分からない、せっかく分析基盤を作ったのにユーザが利用してくれないという課題をお聞きします。
では、そんな課題をお持ちのお客様が多いなか、どのようにしたらデータ活用を成功できるのかというポイントをご紹介します。
成功するデータ活用のポイント Trusted Data Foundation®️
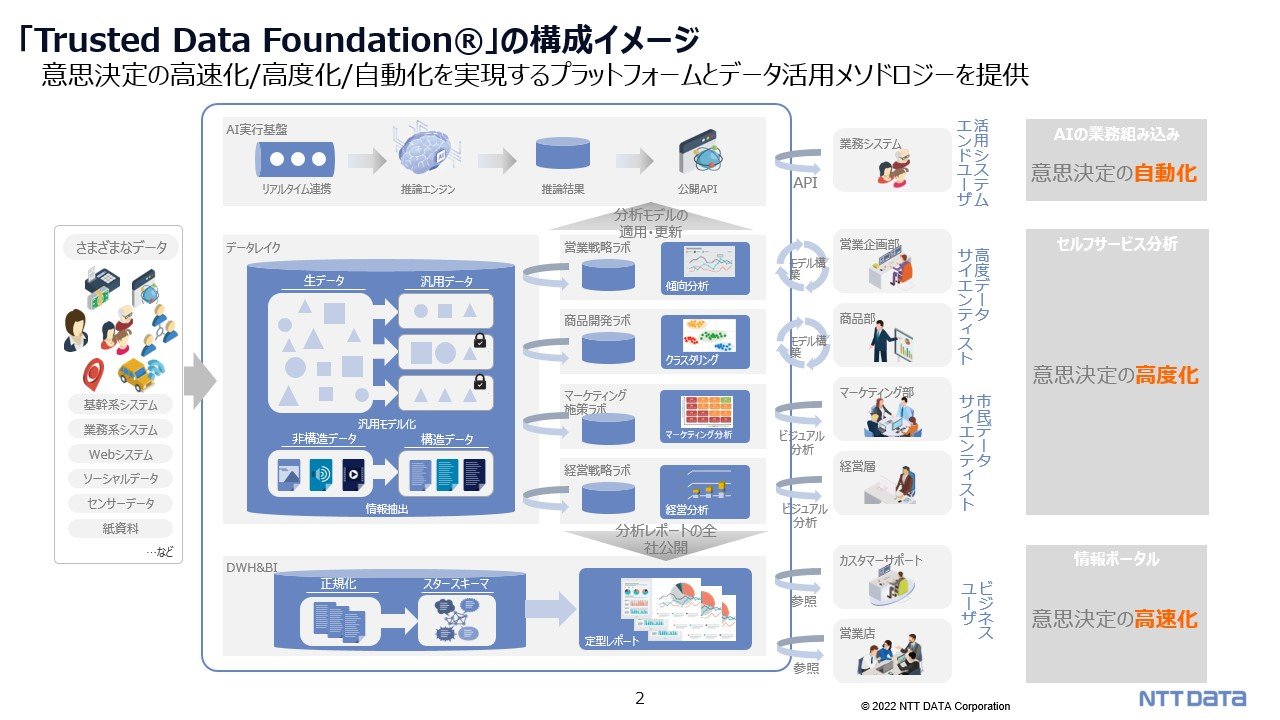
私たちは 「Trusted Data Foundation®️ 」というデータ活用のプラットフォームやメソドロジーのソリューションを提供しております。
社内外のデータを蓄積し、それを AI や機械学習で分析し、その結果を素早く業務に展開できるようなプラットフォームに加え、データを使えるような形にし、ビジネスに活かしていくためのデータ活用のメソドロジーもあわせて提供しております。
そのメソドロジーの一部を紹介させていただきます。
●セルフサービス分析
セルフサービス分析、つまりデータの民主化での最も大きな課題は、ユーザの利活用が進まないということです。システム部門目線でガチガチにガバナンスが効いた環境は、ビジネスユーザのいろんなツールが使いたい、もっと自由に使いたいという実際のニーズとずれていること多いものです。そこで分析基盤を作る時は、ビジネスニーズを取り込んだユーザビリティとガバナンスのバランスがとることが重要です。
データ分析については、せっかくデータサイエンティストを育成したのに、分析が活発化しないというお
客様も非常に多くおられます。データエンジニアやビジネスユーザを巻き込んで、社内に分析の文化やコミュニティを醸成することが重要になってきます。
●データマネジメント
データを活用するためのデータのマネジメントについては、データの中身が分からない、データモデルが分析に適していない、欠損値が多くて使えないなどの理由で、基盤を作ったのにデータがなかなか使われないといった課題があります。
これを解決するためには、運用などのルール策定や組織整備をきちんと定めることが必要ですが、セキュリティや管理統制のためのルールだけでなく、あくまでデータ活用を促進できるようなルールづくりが重要になってきます。
もう 1 つ重要なのが組織体制です。従来型の IT 部門がデータの準備をする方法では、なかなかうまくいきません。そこでデータスチュワード、データマネジメントオフィスといったデータを専門に扱う組織を作る必要があります。
データマネジメントオフィスは、全社横断組織としてデータマネジメントの専門家を集めて組成しました。それとともにデータスチュワードシップという各システムの代表者を集めた仮想組織を作り、全社的なデータの流通や使える化を促進することができております。
●AI の業務組み込み
次に AI の業務組み込みについてですが、最近ではアルゴリズムの選択を自分でやってくれるオートML(マシンラーニング)の仕組みや、精度の劣化を検知してくれる仕組みなどのソリューションが登場しています。世の中の動向やトレンドが急速に変化するなか、それに対応していくために AI のモデルの再学習、更新のライフサイクルを早く回すためのプラットフォームをしっかり作っておく必要があります。
先進顧客が抱える課題と次世代分析基盤「Databricks」「Snowflake」
DX で成功している先進的なお客様の課題をまとめますと、下図のように従来型のデータ分析に限界を感じておられるケースが多くなっています。
DWH(データウェアハウス)、データレイク、データマートなどさまざまなデータストアが乱立。さらに
機械学習や BI を行うことで、分析ワークロードや OLTP(Online Transaction Processing)ワークロード用の環境が必要となります。そのためデータ重複や管理コストの負担が課題となります。また AI や機械学習のモデルの業務適用およびライフサイクルを早く回せないという課題もあります。

こうした課題を解決する方法として、最近では「データメッシュ」「データファブリック」という言葉が行しています。これは、従来のような上流のデータソースシステムからデータを配るという仕組みではなく、どの業務システムからでもデータの生成、使用、分析が可能になるという地方分権的な仕組みです。
それを実現するためのテクノロジーとして最近「モダンデータスタック」という言葉も流行しており、データ仮想化やデータカタログといった社内のデータを素早く流通させるためのテクロノジーが多く登場しています。
その中から「Databricks」と「Snowflake」をご紹介いたします。
●Databricks
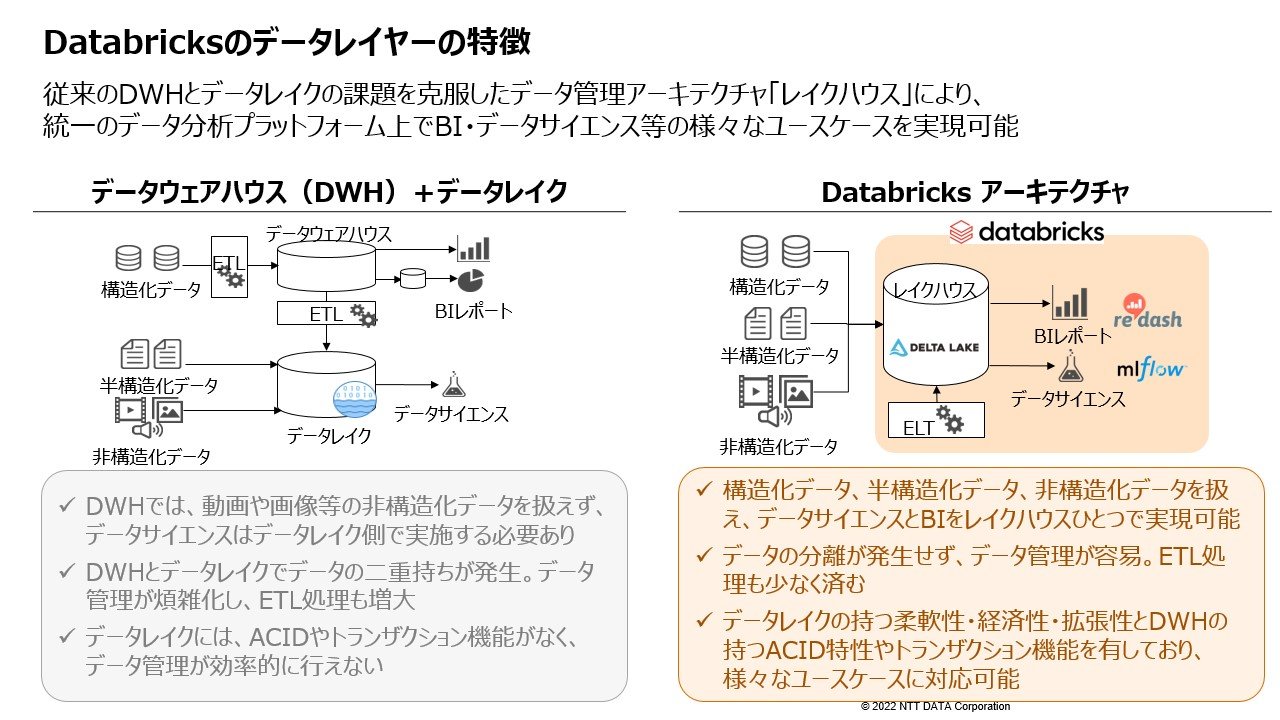
Databricks は、DWH、データレイク、さらに分析、BI、マシンラーニングまで、すべてを 1 つのツールで行ってしまうオールインワンの分析プラットフォームです。
特徴としては、DWH とデータレイク両方の処理を 1 つのプラットフォーム上でできることが大きなポイントです。これまで Hadoop や Spark で行っていた非構造化データを用いた機械学習の大規模分散もこのプラットフォーム 1 つでできます。これまで乱立していたデータストアを 1 つにまとめられるのは大きなメリットです。
もうひとつの特徴は豊富な分析ツール群です。BI ツール、AI・機械学習のための Python を使ったノートブック、AI のライフサイクルを実現する MLflow の機能も持っています。
Databricks はオールインワンツールということで非常に高価と思われるでしょうが従量課金となっており、お試しで少し分析してみるなど気軽に始められるツールとなっています。同時に Hadoop や Sparkでやっていた数ペタバイトの処理もできるという、きわめて小規模から大規模までこのツールひとつで可能という点が画期的です。
https://enterprise-aiiot.nttdata.com/service/databricks
●Snowflake
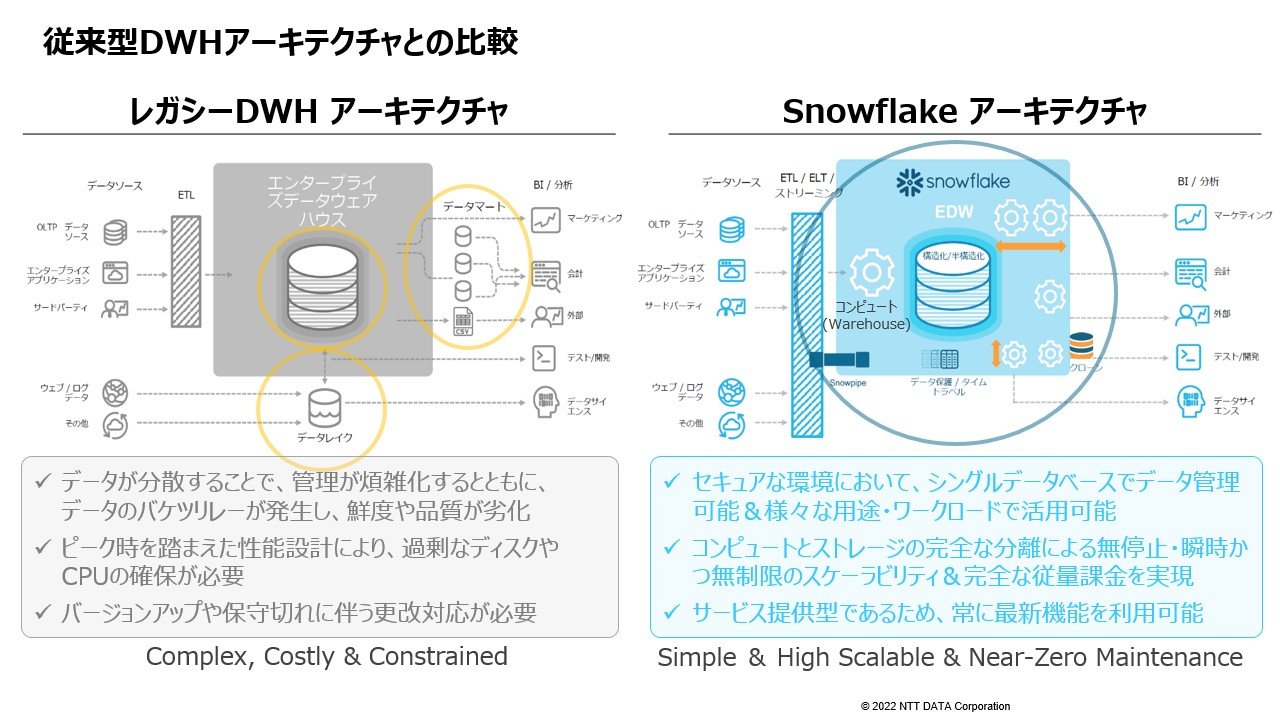
Snowflake は、データを 1 ヶ所に集め、そのデータに対して ビジネスユーザが素早くアクセスし、意思決定できる仕組みを目指して作られています。
特徴は、コンピュータとストレージのリソースが完全に分離していることです。1 ヶ所に集められたデータに対して、処理や分析それぞれに適したワークロードに合わせてコンピュータリソースを用意して処理していきます。データの重複がなく、さまざまなワークフローに対応できる画期的な仕組みとなっています。
もう 1 つの強みとして、優れたデータシェアリング機能があります。データシェアリングというのは、異なるアカウント間でデータを共有して、あたかも自分のデータベースにデータがあるかのように共有できる仕組みです。
例えばサプライチェーンの中の情報を異なる会社間で共有したり、金融の取引のデータを即座に会社間で共有したりすることが可能です。
このように優れたデータシェアリング機能により、会社間のデータ共有や社内の部署間のデータ共有がシームレスに行えるようになり、さまざまなビジネス創出や社内のデータ連携にご活用いただけるかと思います。
今回は データドリブン経営のための意思決定の高速化、高度化、自動化によりビジネス変革を実現する Trusted Data Foundation の®ソリューションの一部をご紹介しました。ぜひ皆様と一緒にデジタルトランスフォーメーションを進めてまいりたいと考えております。






